AI(Artificial Intelligence,人工智慧)已進入關鍵轉折點,其技術能力已被驗證。在 2026 年,如今的問題在於「AI 能否在企業規模下被信任並穩定運行」。對一般使用者而言,已習慣 ChatGPT、Gemini 或 Perplexity 偶爾出錯並自行判讀。但在企業場景中,這樣的容錯空間並不存在。AI可能涉及高風險財務決策、受監管產業與跨國營運,一旦逐步走向自主執行,錯誤將在流程、系統與決策中持續擴散,且隨規模與自主性提高而放大。
企業導入 AI 的最大障礙在於「信任」,而關鍵來自數據本身。AI 系統會直接反映數據的品質、結構與一致性,但多數企業數據並非為 AI 設計,並非所有數據都具備 AI 可用(AI-Ready)條件。名稱未對齊、重複數據、欄位定義不一致等等問題,在人工流程中可被補正,進入 AI 後卻會被放大,直接影響分析與決策。因此,數據是否能被一致理解,成為企業級 AI 成功與否的核心,也是最常被低估的環節。
隨著 AI 快速發展,臺灣數位發展部於 2025 年 10 月發布《AI-Ready Data 詮釋資料框架指標指引》,強調數據品質與治理的重要性。鄧白氏(Dun & Bradstreet)本文聚焦「什麼是 AI-Ready 的數據」,多個關鍵維度說明,評估數據是否能支撐可信且可規模化運行的 AI 系統。
AI 可用數據(AI Ready Data)是指具備一致識別、明確來源、標準化結構、可被機器使用,並內建治理能力的數據,能支撐 AI 系統在企業規模下穩定運行。透過適當的數據整備,使其能被 AI 系統有效運用,並作為可靠的應用基礎。
根據數位發展部《AI Ready Data 詮釋資料框架指標指引》,AI Ready Data 應同時具備可查找性(Findability)、可近用性(Accessibility)、互通性(Interoperability)、再利用性(Reusability)、可信任性(Trustworthiness)五大構面,並透過十四項指標建立完整的評估標準。指引進一步指出,若缺乏足夠的詮釋資料(Metadata),例如數據來源、時間範圍、標註方式與使用限制,將直接影響模型效能、應用可靠性與再利用能力。換言之,AI Ready Data 的核心,在於 AI 能否在這些數據上持續做出可靠、可追溯、可被信任的判斷。
圖:AI-Ready Data 詮釋資料框架指標構面示意圖(來源:數位發展部)
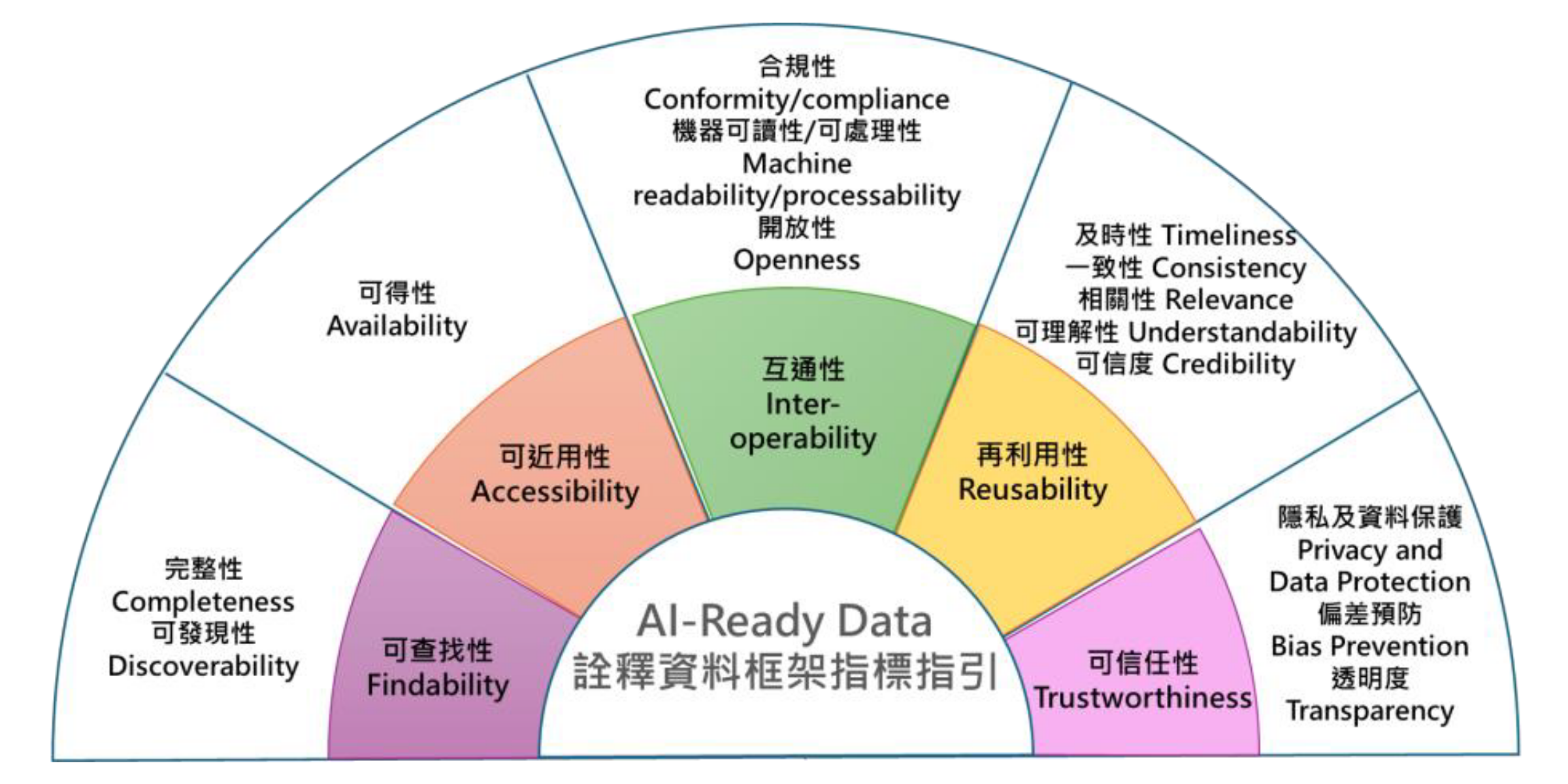
該指引屬於「標準與評估框架」,核心在於回答「什麼樣的數據才算具備 AI Ready 條件?」其評估重點聚焦於數據的機器可讀性(Machine Readability),以及跨資料集整合程度(Degree of Cross Dataset Integration),也就是數據是否能被 AI 理解、處理,並在不同系統與應用場景中持續運作,代表 AI Ready Data 的關鍵在於能否真正被機器使用。
在國際發展上,歐盟 FAIR 原則,以及聯合國教科文組織(UNESCO)與經濟合作與發展組織(OECD)對負責任 AI 的倡議,皆持續強化相同方向,強調數據需具備語意可解釋性與跨域整合能力,以支援 AI 的訓練與實務應用。數發部的指引亦是在此國際趨勢下,建立符合臺灣本國情境的評估架構與實務指引。
在一般使用情境中,人們已經習慣生成式 AI 偶爾出現錯誤,並透過人工修正降低影響。但在企業場景中,AI 可能被用於信用決策、供應商評估、KYC/KYX、法遵、採購、行銷、業務優先排序與跨系統自動化流程等等,這些情境對數據品質、來源透明度與可驗證性有更高要求。鄧白氏也持續強調,企業級 AI 的基礎是經驗證、可被信任的商業數據。
企業環境中,AI 的可靠性取決於數據,而不只是模型本身。當 AI 進入決策流程,小型數據誤差可能被放大為系統性風險。因此,企業要回答的問題是「AI 使用的數據,是否值得信任」。
「當數據已具備 AI Ready 條件後,AI 是否真的能在企業中穩定運作並支撐決策?」
在釐清 AI Ready Data 的定義與標準之後,企業仍需面對這個更為實務的問題。國內外指引著重於定義與評估數據是否具備 AI 可用條件,而在企業實務中,更進一步的挑戰,在於如何將這些數據轉化為可持續運行的 AI 能力。
基於此,鄧白氏從企業應用與決策角度出發,提出五大關鍵維度:確定性識別、數據來源與權利、AI 可用結構、可近用性與互通性、治理與合規,作為補足標準框架的實務方法,將 AI-Ready Data 轉化為可落地的營運能力,包括建立一致且可驗證的企業識別機制、確保數據來源與使用權清晰,使數據具備可被 AI 理解與運用的結構,同時能在不同系統之間流動並被持續調用,並在整個過程中嵌入治理與合規機制。
鄧白氏專家的應用觀點回應「AI 是否能真正運作」,並將 AI Ready Data 從概念定義轉化為企業可執行的能力基礎。以下為鄧白氏五大關鍵維度指標的說明:
AI-Ready 的第一步,是讓數據能穩定對應到現實世界中的真實實體。當同一家公司在不同系統中有不同名稱、不同格式,甚至被建立成多筆紀錄時,人或許可以靠經驗判斷,但 AI 不會自動理解它們是否指向同一個對象。這會導致實體被錯誤拆分、錯誤合併,進一步影響報表、模型與決策結果。數據應具備明確欄位定義、結構一致性與跨數據集整合能力,才能提升 AI 的應用可行性。
對鄧白氏而言,這也是為什麼鄧白氏環球編碼®(D U N S® Number)被視為企業識別的核心基礎。鄧白氏最新 AI 數據解決方案 D&B.AI™ 架構中,以 D U N S® Number 作為大語言模型(LLM)與多代理工作流程中的識別錨點,協助企業在跨平臺、跨系統、跨組織的情境下維持一致的企業身分理解。沒有一致識別,AI 看到的就不是同一個商業世界。
數據正確,並不代表數據可以被安全或合法地使用。AI-Ready Data 必須回答:數據從哪裡來?如何取得?是否有授權?是否可用於訓練、分析、決策或自動化流程?
「可信任性」在國內外多被列為 AI-Ready Data 的核心構面之一,強調數據應具備來源透明、處理過程可追溯、偏差預防資訊,以及隱私保護與倫理規範等等能力,這些也是企業在 AI 應用中辨識風險、界定責任與建立外部信任的重要基礎。
在資訊高度分散的環境下,決策者往往難以及時取得具脈絡且可驗證的商業洞察。透過整合數據與對話式查詢工具,例如鄧白氏 ChatD&B™ 商業數據快搜,讓使用者能了解回應是透過哪些工具與數據產生,企業得以加速資訊取得與決策流程,並且具備清晰來源與完整脈絡。
因此,在企業級 AI 應用中,關鍵在於是否能清楚說明數據從何而來、如何被處理,以及如何產生結果。若缺乏這些可追溯與透明的基礎,AI 的可信度將難以建立,企業亦難以有效控管其帶來的風險。
很多企業其實不缺數據,缺的是 AI 能用的數據。對人可讀,並不代表對 AI 可用。要使數據達到 AI Ready,關鍵在於能否讓 AI 系統與自治代理(autonomous agents)以一致使用的形式呈現。這需要在結構化的同時保留脈絡(context)、關聯性(relationships)、操作限制(operational constraints),使 AI 能正確理解並可靠地採取行動,而不只是透過傳統 API 提供存取,以提升數據的機器可讀性與可自動化處理能力。
隨著 AI 應用走向代理型工作流程(Agentic Workflows),數據的要求進一步提升,必須能被理解、整合,並在不同系統與流程中持續運作。在此基礎上,D&B.AI™ 透過 MCP(Model Context Protocol,模型上下文協定)伺服器等等標準化機制,將數據轉化為可被代理運作的形式,包括提出了 Agent-Ready Data(AI 代理專用數據)、Agent-Ready Answers(AI 代理專用答案),使數據具備脈絡與可行動性,讓 AI 與代理(AI Agents)能穩定存取、理解並執行任務,進一步支撐決策流程。
AI Ready 的核心,在於能否被機器穩定理解、調用,並在實際情境中被可靠地運用。
企業數據通常分散在雲端平臺、SaaS 系統、內部主數據庫與各式流程工具中。若數據無法在這些環境之間流動,即使本身品質良好,也很難真正支撐 AI 的規模化落地。「可近用性」與「互通性」是 AI-Ready Data 的核心要求之一,數據需可穩定取得,具備明確下載或存取機制,並利於跨平臺、跨系統交換與整合。
如果數據受限於格式不一致、數據孤島或存取限制,將直接削弱 AI 的使用效率與可擴展性。鄧白氏 AI 數據解決方案可透過合作夥伴生態系以及其他方式提供,並透過 A2A(Agent‑to‑Agent,代理對代理協定)與 MCP,支援多代理與多平臺間的數據調用與合作。企業在評估 AI-Ready Data 時,要注意「數據是否能在需要的地方被穩定使用」。不能流動的數據,無法成為可擴展的 AI 能力。
鄧白氏(Dun & Bradstreet)的數據在設計之初,即經過結構化、標準化處理,並納入情境與關聯設計,為 AI 可用(AI‑Ready Data)並能有效支援其在不同決策場景中的理解與判斷。點此查看鄧白氏即時更新、值得信賴且 AI 可用的數據基礎。
當 AI 進入企業核心流程,治理與合規就成基本前提。企業需要清楚掌握 AI 使用的數據來源、結果如何產生、是否符合內部政策與法規,以及是否具備追溯與審計能力。在可信任性構面下,應涵蓋透明度、偏差預防、隱私與數據保護等等關鍵要素。
AI‑Ready Data 必須將數據治理內建於架構中,而非事後補強,並強化可解釋性、可稽核性,以及依授權範圍提供回應與負責任 AI(Responsible AI)的透明揭露。企業若要將 AI 應用於高風險與高價值場景,需建立可監督、可驗證且可控管的數據與 AI 運作基礎。缺乏治理的數據,即使可用,也難以成為值得信任的 AI 基礎。
當企業理解 AI Ready Data 條件後,下一步是確認「AI 能否在企業中穩定運作」。目前多數企業的落差在於,數據已存在,甚至已部分清理與整合,但 AI 仍無法持續產出可被信任的分析與決策。關鍵原因在於,缺乏能讓 AI 穩定調用、理解、驗證並跨流程運作的數據環境。
鄧白氏專家認為,下一階段企業級 AI 將走向代理型,而代理型 AI(Agentic AI)其基礎必須建立在可信任數據(Trusted Data)之上。例如,透過 ChatD&B™ 的統一提示介面(Unified Prompt Interface, UPI),以自然語言串接企業內外數據與 AI 能力;或是針對信用風險、供應商風險、KYC/KYX 身分驗證導入流程等等情境設計專用 agents;以及透過 MCP 提供具結構與脈絡的 Agent‑Ready Data,讓 AI 能在實際商業流程穩定運作與執行。
AI 只有建立在可信且具脈絡的數據之上,才能真正產生企業級決策價值。這也體現鄧白氏在 AI 時代的角色:
企業可透過以下五個關鍵問題(包含但不限於),從多個面向評估數據是否已準備好 AI 應用:
若上述各項面向中有任一關鍵條件無法明確回答,企業的 AI 導入多半仍停留在實驗或試點階段,難以進一步擴展為可規模化且可被信任的應用情境。
若企業希望讓數據真正成為 AI-Ready,可優先從以下方向著手:
2026 年,企業如今面臨加速導入 AI 的壓力。投資全面展開,回報期待持續升高,技術演進亦不斷加速。然而,能夠長期創造價值的企業,關鍵在於是否穩健建立基礎。當識別清楚、脈絡一致、權限明確,且數據完善治理時,AI 才能穩定運作,並進一步實現規模化擴展。
從工具到流程,再到決策,AI 的角色正快速演進,但決定企業能否從「可用」邁向「可被信任」,仍在於數據是否具備 AI Ready 的條件。在 AI 時代,企業成長的關鍵,在於能否將數據轉化為可被信任、可被推理,並可支持行動的商業脈絡。
鄧白氏由企業數據庫(Data Cloud)轉型為全球商業圖譜(D&B Global Commercial Graph™),將數據從靜態紀錄轉化為動態連結。企業不僅需要知道「這家公司是誰」,更需要理解其關係網絡、控制結構、供應鏈流動,這些關聯是 AI 時代決策所需的關鍵脈絡,而非單一數據點。
企業若要讓 AI 進入核心營運,必須先讓數據成為可被理解、整合與再利用,且值得信任的基礎資產。這也意味著,AI 的競爭已由模型能力,進一步轉向數據能力,並最終體現在決策能力的差異上。AI 的起點,在於數據基礎。
鄧白氏 D&B.AI™ 以可信且經驗證的數據為核心,協助企業強化數據整合能力,支撐 AI 工作流程運作,並促進跨域數據的流通與再利用。讓數據成為 AI Ready,並持續維運這項基礎能力,是企業將 AI 從實驗導入推進為長期價值的關鍵。

